![[장영한] 투자 북클럽 3기](https://img.wowtv.co.kr/MainManage_DAYADD/134291562485856398.jpg)


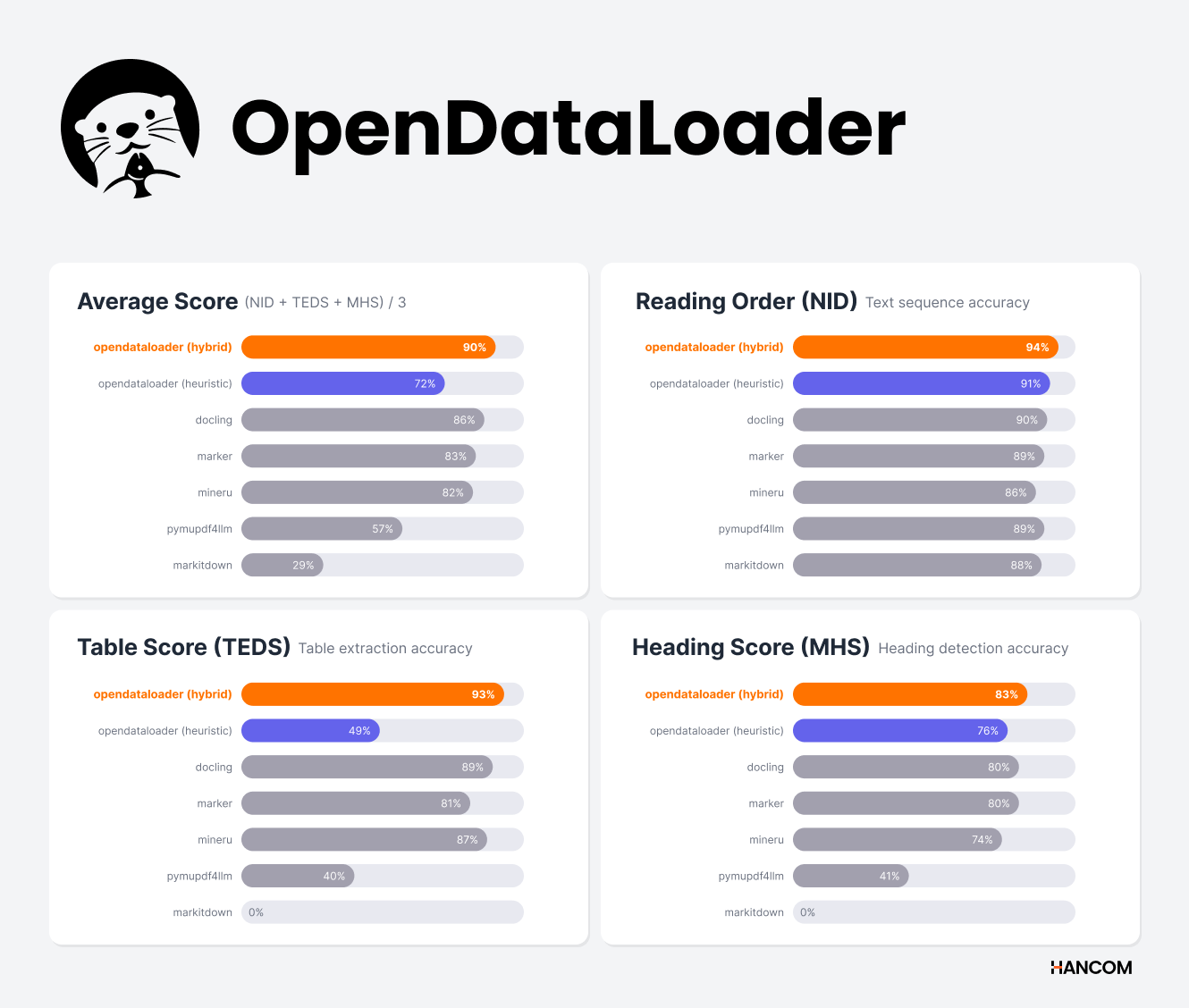
한글과컴퓨터가 오픈소스 PDF 데이터 추출 부문에서 벤치마크 1위 성능을 달성한 ‘오픈데이터로더 PDF v2.0’을 12일 공개했다.
이번 버전의 가장 큰 특징은 AI 방식과 직접 추출 방식을 결합한 하이브리드 엔진이다. 기업과 개발자는 외부 서버로의 데이터 유출 우려없이 완벽하게 차단된 로컬 환경에서 고성능 PDF 데이터 추출 기능을 무료로 활용할 수 있다.
문서 내 복잡한 요소를 추출하는 무료 AI 애드온 4종이 기본 탑재됐다.
‘광학문자인식(OCR)’은 이미지 기반 PDF와 스캔 문서의 텍스트 인식률을 높였고, ‘표 추출’은 초경량 AI 모델로 병합된 셀 등 복잡한 표 구조를 정밀하게 분석한다. ‘수식 추출’은 과학·수학 논문의 복잡한 수식을 로컬 환경에서 인식하며, ‘차트 분석’은 차트가 의미하는 맥락을 문장 형태로 설명한다.
이들 애드온은 도클링(Docling) 등 타사 오픈소스 AI 모델과 호환되도록 구현됐다.
오픈데이터로더 PDF v2.0은 자체 벤치마크 테스트에서 1위 수준의 성능을 기록했다. 오픈소스의 핵심 가치인 투명성을 보여주기 위해 벤치마크 테스트 데이터와 재현 가능한 상세 코드를 공식 깃허브(GitHub) 저장소에 모두 공개했다.
올해 하반기에는 독자 문서 AI 기술을 집약한 상용 AI 애드온을 출시할 계획이다. 나아가 AI가 문서 구조를 분석해 접근성 태그를 자동 생성하는 기술을 오픈소스 최초로 탑재한다.
정지환 한컴 최고기술책임자는 “향후 상용 AI 애드온과 접근성 설루션을 통해 전 세계의 PDF 문서가 AI에 활용되는 것은 물론, 모든 사람에게 열린 문서가 되도록 글로벌 생태계를 선도하겠다”고 말했다.
관련뉴스










