


인공지능(AI) 업체와 콘텐츠 제작사가 ‘창과 방패’ 전쟁을 벌이고 있다. 웹사이트 내 자료를 무단 수집해 학습 데이터로 활용하는 AI 기업에 대응하기 위한 솔루션이 늘어나면서 전쟁 양상이 한층 치열해지는 모양새다.
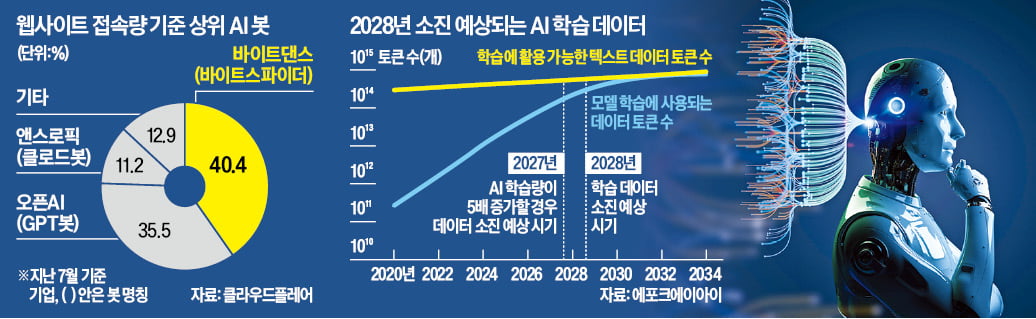
AI 봇은 웹사이트의 텍스트, 이미지, 영상 등 정보를 자동으로 수집하는 프로그램이다. 이렇게 모은 데이터는 AI 모델 학습을 위해 쓰인다. 아마존, 오픈AI, 앤스로픽 같은 테크 기업은 자체 AI 봇으로 인터넷상 데이터를 자유롭게 얻는다. 매슈 프린스 클라우드플레어 최고경영자(CEO)는 “AI 봇은 콘텐츠 제작자의 동의 없이 하루에도 수천 번씩 웹사이트를 스캔한다”며 “AI 오딧을 활용하면 AI 봇이 웹사이트에 접근하는 이유, 시기, 빈도 등을 파악할 수 있다”고 설명했다.
클라우드플레어의 다음 목표는 웹사이트 관리자가 AI 기업과 거래할 수 있는 플랫폼을 만드는 것이다. 기존에 무상으로 활용하던 학습 데이터에 대가를 지불하게 만들겠다는 의미다.
일반적으로 AI 봇은 웹사이트 운영자가 특정한 AI 봇의 접근을 개별적으로 금지하는 방식으로 차단한다. AI 봇 명칭을 정확히 알지 못하면 막을 수 없다. AI 기업이 AI 봇 개편 사실을 알리지 않으면 새로운 봇의 이름이 퍼지기 전까지 데이터를 긁어갈 수 있다는 얘기다.
국내 인터넷 이용자가 생산하는 콘텐츠도 AI 봇의 타깃이 되고 있다. 업계 관계자는 “오픈AI가 GPT-4를 공개할 당시 모델이 국내 뉴스 댓글 등에서 볼 수 있는 신조어를 인식하고 사용했다”며 “국내 포털 사이트의 한국어 데이터를 크롤링하지 않고선 불가능한 일”이라고 말했다. 국내 업체인 네이버는 ‘하이퍼클로바X’ 같은 자체 AI 모델 학습을 위해 이용자 약관에 따라 블로그와 카페에 올라온 게시글을 사용한다.
AI 기술이 발전하고 콘텐츠 제작자 권리를 둘러싼 갈등이 심해지면서 각국 정부도 이 문제에 개입하기 시작했다. 개인정보보호위원회는 7월 ‘AI 개발·서비스를 위한 공개된 개인정보 처리 안내서’를 발간하고 AI 학습 데이터 수집 기준을 마련했다. 유럽연합(EU), 미국 등도 인터넷에 공개된 정보를 AI 학습에 활용하기 위한 지침 마련에 나섰다.
황동진 기자 radhwang@hankyung.com
AI 봇 차단 도구 등장
소프트웨어 보안 기업 클라우드플레어는 24일 AI 봇의 웹사이트 접근을 제어할 수 있는 도구 ‘AI 오딧’을 공개했다. 콘텐츠 창작자는 AI 오딧으로 오픈AI 같은 기업의 AI 봇이 자신의 사이트에 접근하는 것을 막고 콘텐츠 사용 여부를 통제할 수 있다. 자신의 저작물이 허락 없이 AI 학습에 이용되는 것을 방지할 수 있다. 새로 등장하는 봇까지 실시간으로 탐지하고 차단할 수 있도록 시스템을 자동화한 점도 눈에 띄는 특징이다.AI 봇은 웹사이트의 텍스트, 이미지, 영상 등 정보를 자동으로 수집하는 프로그램이다. 이렇게 모은 데이터는 AI 모델 학습을 위해 쓰인다. 아마존, 오픈AI, 앤스로픽 같은 테크 기업은 자체 AI 봇으로 인터넷상 데이터를 자유롭게 얻는다. 매슈 프린스 클라우드플레어 최고경영자(CEO)는 “AI 봇은 콘텐츠 제작자의 동의 없이 하루에도 수천 번씩 웹사이트를 스캔한다”며 “AI 오딧을 활용하면 AI 봇이 웹사이트에 접근하는 이유, 시기, 빈도 등을 파악할 수 있다”고 설명했다.
클라우드플레어의 다음 목표는 웹사이트 관리자가 AI 기업과 거래할 수 있는 플랫폼을 만드는 것이다. 기존에 무상으로 활용하던 학습 데이터에 대가를 지불하게 만들겠다는 의미다.
차단 우회 기술…AI 기업들 대응 나서
AI 봇 차단 수요가 증가하면서 AI 기업도 차단을 우회하기 위해 AI 봇을 개편하고 있다. 온디바이스 AI 기능 강화에 나선 애플은 지난 6월 ‘애플봇-익스텐디드’를 내놨다. 7월엔 메타와 오픈AI가 나란히 새로운 AI 봇을 공개했다.일반적으로 AI 봇은 웹사이트 운영자가 특정한 AI 봇의 접근을 개별적으로 금지하는 방식으로 차단한다. AI 봇 명칭을 정확히 알지 못하면 막을 수 없다. AI 기업이 AI 봇 개편 사실을 알리지 않으면 새로운 봇의 이름이 퍼지기 전까지 데이터를 긁어갈 수 있다는 얘기다.
국내 인터넷 이용자가 생산하는 콘텐츠도 AI 봇의 타깃이 되고 있다. 업계 관계자는 “오픈AI가 GPT-4를 공개할 당시 모델이 국내 뉴스 댓글 등에서 볼 수 있는 신조어를 인식하고 사용했다”며 “국내 포털 사이트의 한국어 데이터를 크롤링하지 않고선 불가능한 일”이라고 말했다. 국내 업체인 네이버는 ‘하이퍼클로바X’ 같은 자체 AI 모델 학습을 위해 이용자 약관에 따라 블로그와 카페에 올라온 게시글을 사용한다.
AI 기술이 발전하고 콘텐츠 제작자 권리를 둘러싼 갈등이 심해지면서 각국 정부도 이 문제에 개입하기 시작했다. 개인정보보호위원회는 7월 ‘AI 개발·서비스를 위한 공개된 개인정보 처리 안내서’를 발간하고 AI 학습 데이터 수집 기준을 마련했다. 유럽연합(EU), 미국 등도 인터넷에 공개된 정보를 AI 학습에 활용하기 위한 지침 마련에 나섰다.
황동진 기자 radhwang@hankyung.com
관련뉴스










