

<앵커>
4차 산업혁명 시대의 쌀이라 불리는 데이터.
방대한 양의 데이터 수집에 어려움을 겪는 스타트업들을 위해 정부는 `데이터 댐` 사업을 추진하고 있습니다.
공짜로 빅데이터를 활용할 수 있게 한다는 취지인데 정작 데이터를 필요로하는 스타트업들은 이를 활용하기 어렵다고 지적합니다.
양현주 기자가 보도합니다.
<기자>
지난해부터 공공데이터를 활용해 비즈니스 모델 개발을 시도해 온 스타트업 대표 함동수 씨.
황 씨는 올해 초 정부의 데이터 댐 대신 자체적으로 데이터를 수집하기로 결정했습니다.
공공데이터를 통해 유의미한 사업모델을 발굴하기 어렵다고 판단했기 때문입니다.
공공 데이터 업데이트가 느리고 불규칙해 안정적으로 사업을 꾸려가기엔 어려움이 많기 때문입니다.
[함동수 아몬드 대표 : 스타트업들 입장에선 공공 데이터 같은 비정형을 받을 때 꾸준히 수혈을 받아야 하거든요. 이걸 지자체나 정부에서 주기 전까지 받을 수 없다면 스타트업들 입장에선 손 놓고 있을 수밖에 없고]
데이터 질에 대한 불만도 나옵니다.
일상생활에서 사용되는 언어를 데이터화한 `자연어 데이터`는 보통 상담채널이나 카카오톡 대화 내용 등을 동의 받은 후 수집됩니다.
그런데 공공 데이터 사이트 AI허브에서 제공하는 자연어 데이터는 실제 대화내용이 아닌 인위적으로 연출된 내용이었습니다.
배우를 고용하고 특정 상황을 가정해 만들어진 건데, 이 경우 `진짜 대화`에 비해 데이터 질이 떨어질 수밖에 없다는 게 스타트업들의 입장입니다.
또한 시나리오로 가공된 데이터를 수집하게 되면 데이터 양이 부족할 수밖에 없다고도 지적합니다.
과기부는 개인정보 보호 문제로 인해 어쩔 수 없이 시나리오 기반 대화를 선택했다는 입장입니다.
이에 스타트업들은 공공데이터에만 의존할 수 있는 상황이 아니니 기업이 자체적으로 데이터 수집을 원활히 할 수 있도록 제도적 방안이 함께 갖춰져야 한다고 지적합니다.
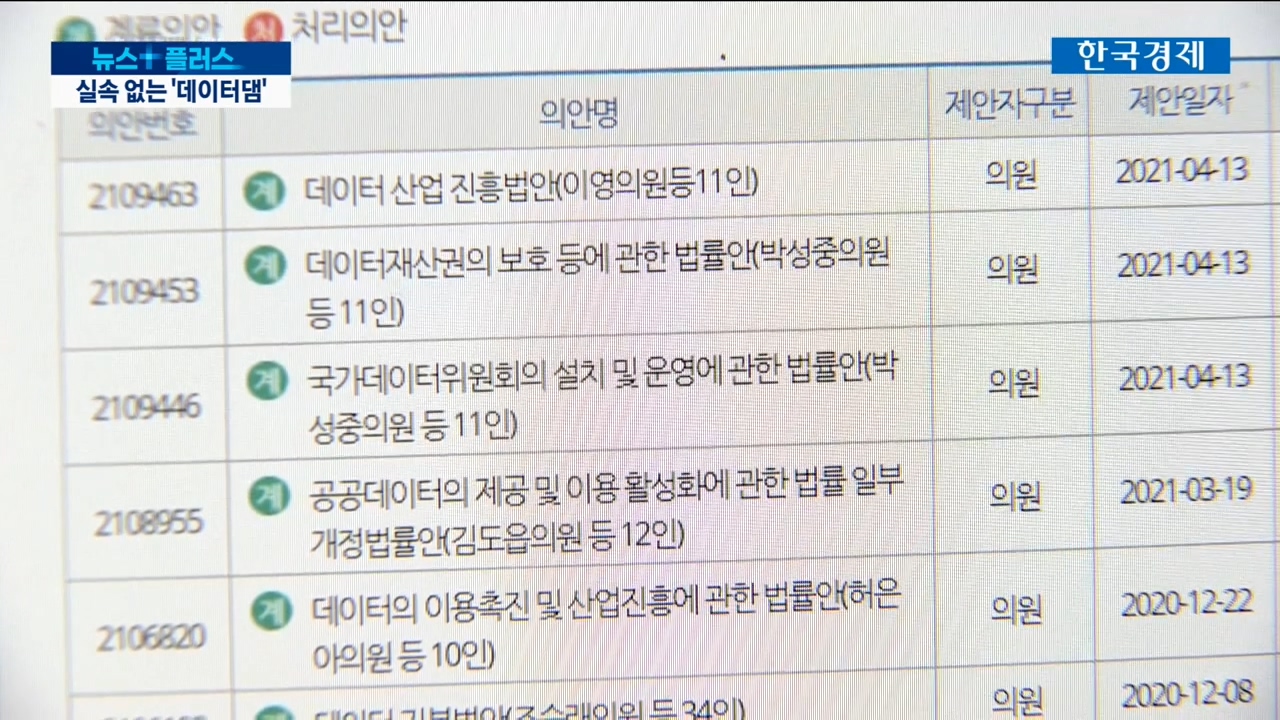
현재 민간 데이터의 거래와 활용 등을 위한 기본 법제는 마련돼 있지 않은 상황.
국회에 관련 법안들이 여러 개 발의됐지만 모두 계류된 상태입니다.
데이터 3법이 통과된 후, 4차 산업의 물꼬는 텄지만 이를 활용할 수 있는 방안은 부족한 실정입니다.
한국경제TV 양현주입니다.
4차 산업혁명 시대의 쌀이라 불리는 데이터.
방대한 양의 데이터 수집에 어려움을 겪는 스타트업들을 위해 정부는 `데이터 댐` 사업을 추진하고 있습니다.
공짜로 빅데이터를 활용할 수 있게 한다는 취지인데 정작 데이터를 필요로하는 스타트업들은 이를 활용하기 어렵다고 지적합니다.
양현주 기자가 보도합니다.
<기자>
지난해부터 공공데이터를 활용해 비즈니스 모델 개발을 시도해 온 스타트업 대표 함동수 씨.
황 씨는 올해 초 정부의 데이터 댐 대신 자체적으로 데이터를 수집하기로 결정했습니다.
공공데이터를 통해 유의미한 사업모델을 발굴하기 어렵다고 판단했기 때문입니다.
공공 데이터 업데이트가 느리고 불규칙해 안정적으로 사업을 꾸려가기엔 어려움이 많기 때문입니다.
[함동수 아몬드 대표 : 스타트업들 입장에선 공공 데이터 같은 비정형을 받을 때 꾸준히 수혈을 받아야 하거든요. 이걸 지자체나 정부에서 주기 전까지 받을 수 없다면 스타트업들 입장에선 손 놓고 있을 수밖에 없고]
데이터 질에 대한 불만도 나옵니다.
일상생활에서 사용되는 언어를 데이터화한 `자연어 데이터`는 보통 상담채널이나 카카오톡 대화 내용 등을 동의 받은 후 수집됩니다.
그런데 공공 데이터 사이트 AI허브에서 제공하는 자연어 데이터는 실제 대화내용이 아닌 인위적으로 연출된 내용이었습니다.
배우를 고용하고 특정 상황을 가정해 만들어진 건데, 이 경우 `진짜 대화`에 비해 데이터 질이 떨어질 수밖에 없다는 게 스타트업들의 입장입니다.
또한 시나리오로 가공된 데이터를 수집하게 되면 데이터 양이 부족할 수밖에 없다고도 지적합니다.
과기부는 개인정보 보호 문제로 인해 어쩔 수 없이 시나리오 기반 대화를 선택했다는 입장입니다.
이에 스타트업들은 공공데이터에만 의존할 수 있는 상황이 아니니 기업이 자체적으로 데이터 수집을 원활히 할 수 있도록 제도적 방안이 함께 갖춰져야 한다고 지적합니다.
현재 민간 데이터의 거래와 활용 등을 위한 기본 법제는 마련돼 있지 않은 상황.
국회에 관련 법안들이 여러 개 발의됐지만 모두 계류된 상태입니다.
데이터 3법이 통과된 후, 4차 산업의 물꼬는 텄지만 이를 활용할 수 있는 방안은 부족한 실정입니다.
한국경제TV 양현주입니다.
관련뉴스










