
![[장영한] 투자 북클럽 1기](https://img.wowtv.co.kr/MainManage_DAYADD/134255436888937226.png)

LG AI연구원이 9일 텍스트와 이미지를 동시에 이해하고 추론하는 멀티모달 AI 모델 ‘엑사원(EXAONE) 4.5’를 공개했다.
‘엑사원 4.5’는 LG AI연구원이 자체 개발한 비전 인코더(Vision Encoder)와 거대언어모델(LLM)을 하나의 구조로 통합한 비전-언어 모델(VLM)이다.
이번 모델은 독자 AI 파운데이션 모델 프로젝트에서 개발 중인 ‘K-엑사원’의 모달리티 확장을 위한 준비 단계이다.
‘엑사원 4.5’는 계약서, 기술 도면, 재무제표, 스캔 문서 등 산업 현장에서 실제로 다루는 복합 문서를 정확하게 읽고 추론하는 능력에 강점이 있다.
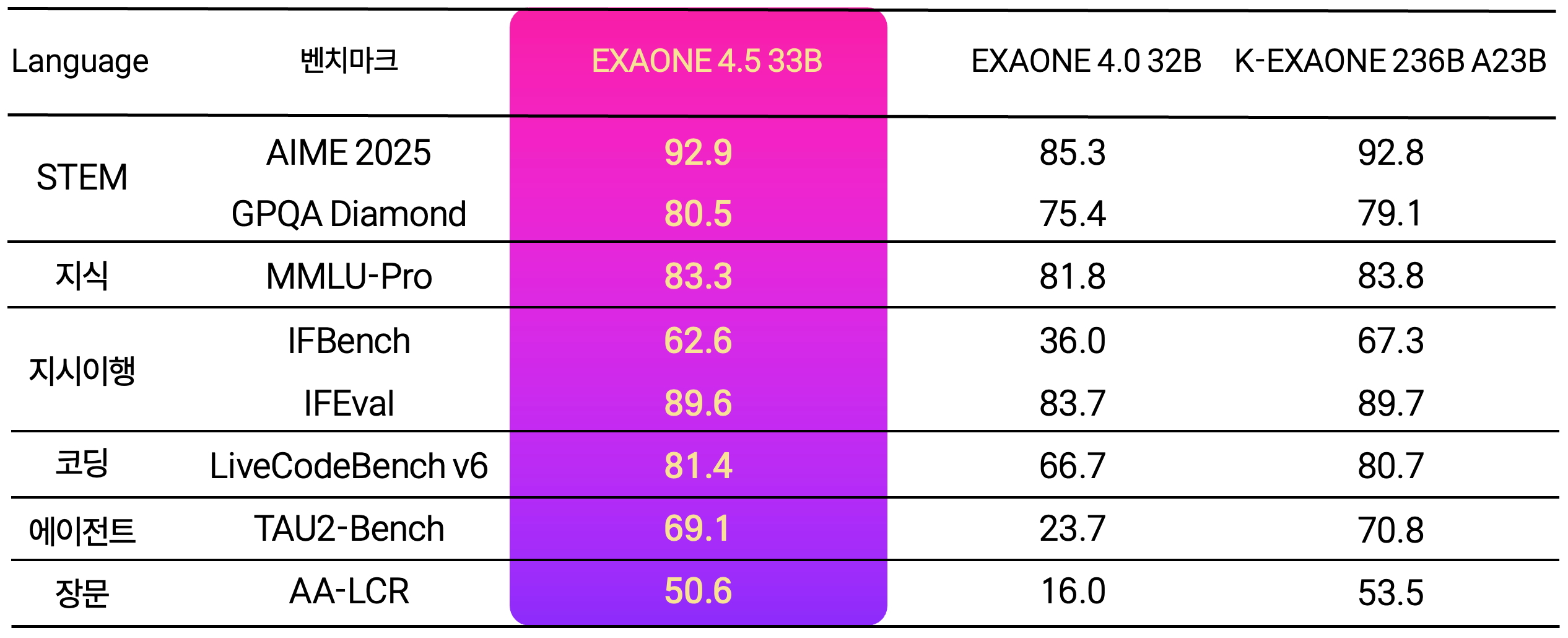
LG AI연구원은 ‘엑사원 4.5’의 멀티모달 AI 모델의 시각 처리와 추론 성능을 평가하는 벤치마크 점수 결과를 공개하며 경쟁력을 입증했다고 밝혔다.
‘엑사원 4.5’는 STEM(과학·기술·공학·수학) 성능을 측정하는 5개 지표 평균 77.3점을 기록해 미국 오픈AI 지피티(GPT)5-mini(73.5점), 앤트로픽 클로드 소넷(Claude Sonnet) 4.5(74.6점), 중국 알리바바 큐웬(Qwen)3 235B(77.0점)를 모두 앞섰다.
일반 시각 이해를 측정하는 3개 지표와, 이미지와 텍스트가 결합된 인포그래픽을 비롯해 복합 정보를 읽어내는 문서 이해 및 추론 성능 평가 지표 5개를 포함한 13개 지표 평균 점수에서도 지피티(GPT)5-mini와 클로드 소넷(Claude Sonnet) 4.5을 넘어섰다.
특히, 코딩 성능 대표 지표인 라이브코드벤치(LiveCodeBench) v6에서는 81.4점으로 구글의 최신 모델 젬마(Gemma) 4(80.0점)를 넘었다.
‘엑사원 4.5’는 성능과 함께 효율성 측면에서도 주목할 만한 결과를 보였다.
‘엑사원 4.5’는 330억 개 파라미터 규모(33B)로 지난해 말 공개한 ‘K-엑사원’의 약 7분의 1 크기이지만, 텍스트 이해 및 추론 영역에서 동등한 수준의 성능을 달성했다.
이는 LG AI연구원이 자체 개발한 하이브리드 어텐션 구조와 멀티 토큰 예측 기반의 고속 추론 기술을 적용한 결과다.
이진식 LG AI연구원 엑사원랩장은 “엑사원 4.5는 LG AI가 시각 정보까지 이해하는 멀티모달 시대로 진입했음을 보여주는 모델”이라며, “음성과 영상, 물리 환경까지 AI의 이해 범위를 확장해 산업 현장에서 실질적으로 판단하고 행동하는 AI를 만들어가겠다”고 말했다.
관련뉴스










