지난 주요뉴스 한국경제TV에서 선정한 지난 주요뉴스 뉴스썸 한국경제TV 웹사이트에서 접속자들이 많이 본 뉴스 한국경제TV 기사만 onoff
-
앤스로픽·구글 이어 오픈AI…업무용 AI 공략 나선 빅테크 2026-03-06 17:45:06
코딩 문제해결 능력을 매기는 ‘SWE-벤치 프로 퍼블릭’ 지표 정답률도 57.7%로 제미나이3.1프로(54.2%)를 상회했다. 오픈AI는 “GPT-5.2 대비 개별 답변에서 오류가 발생할 확률은 33%, 전체 응답에 오류가 포함될 확률은 18% 낮아졌다”고 공개했다. 오픈AI가 GPT-5.4를 ‘업무용 AI’로 내세우고 있는 건 기업용 AI...
- 뉴스 > IT·과학
- 바로가기
-
[테샛 공부합시다] '경기지표' '돈로주의' 문항, 정답률 30%대로 낮아 2026-03-02 09:00:04
설명으로 옳지 않은 것을 고르는 문항의 정답률이 30%대로 낮았다. 정답은 ②번 ‘광공업생산지수는 후행종합지수 산출에 포함되는 경제지표다’이다. 광공업생산지수는 동행종합지수의 구성 지표 중 하나다. 동행종합지수는 현재의 경기 상태를 나타내는 지표다. 다른 보기들을 살펴보면 구매관리자지수(PMI)는 제조업 분...
- 뉴스 >
- 바로가기

-
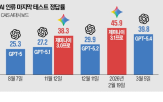
"AI, 펀드매니저 거래 71% 맞혔다"…하버드대 연구 2026-02-25 11:56:26
이번 연구의 AI는 펀드 업무 환경에 따라 예측 결과에 차이가 있었다. 운용 인력이 많고 대내외 경쟁이 치열한 대형 펀드는 평균보다 예측 정확도가 낮았고, 펀드 매니저가 여러 상품을 운용하거나 장기간 근무하는 경우에는 정답률이 더 높아지는 것으로 조사됐다. tae@yna.co.kr (끝) <저작권자(c) 연합뉴스, 무단...
- 뉴스 > 정치
- 바로가기

-
"AI가 과학자처럼 연구 추론"…제미나이3 대규모 업데이트 2026-02-13 15:34:00
각각 87.7%, 82.8%의 정답률로 금메달권 성능을 입증했다. 고급 이론물리학 이해도를 측정하는 CMT 벤치마크에서도 50.5%를 기록했다. 구글은 이번 업데이트에서 ‘연구 맥락 이해’ 능력을 강조했다. 과학자·연구원들과의 협업을 통해 명확한 해답과 가이드라인이 없는 연구 과제를 풀 수 있도록 모델을 고도화했다고...
- 뉴스 > 산업
- 바로가기
-
서울대병원, AI 공개…판독·진료 지원 2026-02-09 16:59:09
국내 의사국가고시(KMLE) 모의 테스트에서 정답률 89%를 기록한 의료 인공지능(AI)이 공개됐다. 서울대학교병원은 헬스케어AI연구원이 개발한 의료 특화 AI 모델 2종을 오픈소스로 공개했다고 9일 밝혔다. 텍스트 기반 의료 AI는 임상 상황을 이해하고 진단·치료 과정에 필요한 추론을 수행하도록 설계됐다. KMLE 모의...
- 뉴스 > IT·과학
- 바로가기
-
디지털로 바뀐 美 SAT서 부정행위 의심…中사이트서 문제 거래 2026-01-29 10:28:57
않다는 지적도 있다. 시험 앞부분에서 정답률이 높아 실력이 뛰어난 것으로 추정되는 응시자에게는 까다로운 문제가 나온다. 또 출제 문항은 문항 수십만개가 있는 문제은행에서 추출된다는 게 칼리지 보드의 설명이다. 현재 SAT는 중국 정부의 제한 방침으로 중국 내에서는 시행되지 않고 있으며, 중국에 사는 응시자들은...
- 뉴스 > 정치
- 바로가기

-
[테샛 공부합시다] '부정적 외부효과' '재정준칙' 문항 정답률 낮아 2026-01-19 10:00:34
고르는 문항의 정답률이 40%대로 낮았다. 정답은 ③번 ‘사회적 한계비용이 사적 한계비용보다 작기 때문에 발생한다’이다. 층간소음은 부정적 외부효과의 대표적 사례다. 부정적 외부효과란 어떤 경제주체의 행위가 제3자의 경제적 후생을 감소시키지만(①번), 그 피해에 대한 적절한 보상이 이루어지지 않는 현상이다....
- 뉴스 >
- 바로가기

-
[테크톡노트] AI 성능 점수의 함정…벤치마크 믿어도 될까 2026-01-17 07:14:00
한 뒤 정답률, 처리 속도, 오류율 등을 수치로 비교하는 방식이다. 대표적인 벤치마크로는 문장 이해와 추론 능력을 평가하는 MMLU, 수학 문제 해결력을 측정하는 GSM8K, 코드 작성 능력을 살피는 HumanEval, 긴 문서 이해 능력을 보는 LongBench 등이 있다. 최근에는 유해 발언 생성 여부나 규칙 준수 수준을 점검하는...
- 뉴스 > 경제
- 바로가기

-
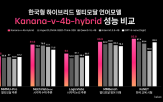
카카오, 스스로 '검산'까지 하는 한국형 멀티모달 AI 공개 2026-01-05 14:58:22
수학 등의 문제에서 한국어의 미묘한 조건들을 놓치지 않아 높은 정답률을 기록했다. 한국의 교육 체계를 기반으로 하는 AI 학력 평가 벤치마크인 ‘KoNET'에서는 92.8점을 획득했다. 이 밖에도 유사한 크기의 글로벌 모델 큐원3-VL-4B, 인턴VL3.5-4B, GPT-5-나노, 국내 모델 과의 성능 평가에서 과학과 공학, 일반...
- 뉴스 > IT·과학
- 바로가기
-
카카오, ‘스스로 생각하고 답변하는’ 한국형 언어모델 공개 2026-01-05 10:57:27
수학 등의 문제에서 한국어의 미묘한 조건들을 놓치지 않고 높은 정답률을 기록했다. 한국의 교육 체계를 기반으로 하는 AI 학력 평가 벤치마크인 ‘KoNET(Korea National Educational Test Benchmark)’에서는 92.8점을 획득했다. 이 밖에도 유사한 크기의 글로벌 모델 Qwen3-VL-4B, InternVL3.5-4B, GPT-5-nano 및 국내...
- 뉴스 > 산업
- 바로가기